
Those advocating emerging technologies and ideas often talk as if IT is a zero sum game. When something new comes along, the assumption is that something old needs to move aside to make way. We have seen this happen on a number of occasions in the data management space, with frequent claims relational databases becoming less and less important.
We went through this loop over a decade ago when someone first spotted that organisations were accumulating a lot of documents, emails and multi-media that didn’t fit neatly into rows and columns. It became trendy to point out that volumes of unstructured data were growing exponentially, and that the centre of gravity for information value was shifting from traditional structured databases to document management systems, collaboration environments, and so on.
The flaw in the argument lies in the confusion between volume and value. In structured databases, like those typically associated with transaction-centric applications such as ERP, logistics, billing and the other core business systems, most or all of the data is valuable.
Individual records might not be worth that much in isolation, but together they represent the organisation’s crown jewels in information terms, which is evident when the value is unlocked through effective business intelligence and analytics capability.
Look at the contents of the average email box or file share, and it’s a different story. Most the information contained in unstructured stores such as these is typically duplicate, inconsequential or simply junk. It’s not just the final version of a document that is stored, for example.
During its production, the chances are that various drafts will have been produced and circulated for review. In storage terms, you are therefore likely to have multiple versions of the document stored in the author’s home directory, multiple copies of each version sitting in reviewers’ mailboxes as attachments, and even more copies created as files are saved to local hard disk drives. Then, to cap it off, the many versions, copies, and copies of copies are pulled back into central backup and archiving systems.
Of course, regulation sometimes dictates you need to keep a lot of that stuff, and various de-duplication and compression technologies can help to manage the volume. But let’s not pretend that all of the office files, email messages, multi-media email attachments, social media chatter, scans of things that have been transcribed into a structured form, and so on, can all be considered valuable business assets.
The business value per Mb of data stored is often minuscule compared to traditional structured data sources, and when you throw noisy or bloated external feeds into the mix (that some organisations are starting to capture and process) the ‘value density’ is even lower.
Speaking volumes
It’s therefore unsurprising that in a recent study on advanced data management, the majority of the 502 respondents participating confirmed that the value of their corporate data was still very much concentrated in structured data stores such as relational database management systems:
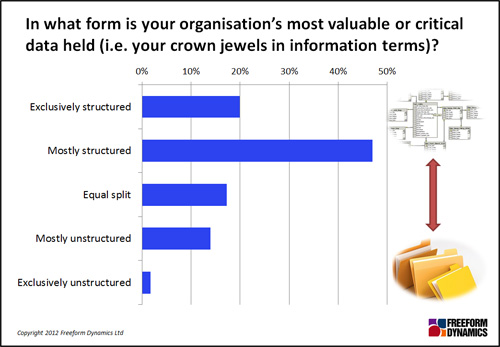
Furthermore, when we asked how this was changing, about one in five indicated a steady shift towards value residing in unstructured data, but approximately the same number said there was a similar shift in the opposite direction. Very few indicated a dramatic change in emphasis, and overall the dynamics were neutral, i.e. the above picture is not changing significantly.
So does that mean that it’s all about maintaining the status quo?
No. The one thing that’s clear is that volumes of data of all kinds are increasing – with structured growing almost as fast as unstructured. This is significant in terms of physical data management, and also because many organisations already struggle to exploit their existing information.
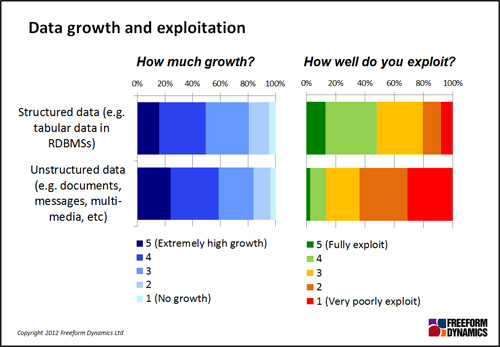
Let’s return to the role of traditional and emerging technologies. While knowledge of newer and more specialist solutions is still limited in the IT professional community, there is a general acknowledgement that all options have their place.
Distributed/scale-out architectures can allow the proverbial needle to be found in the haystack, and elusive correlations to be spotted in very large data sets, all in ways that would previously have been impossible or prohibitively expensive. Meanwhile, in-memory technology can be used to allow on-the-fly analysis against fast moving data, and switch previously batch-based operations to online interactive mode.
But none of this diminishes the role of either general purpose or high performance RDBMS configurations:
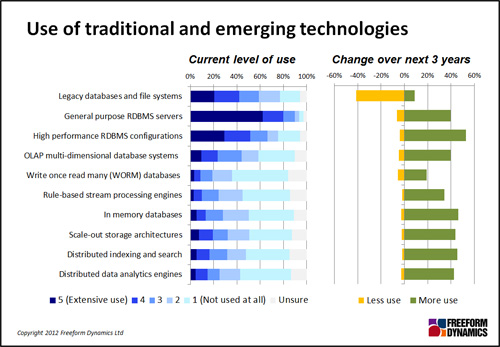
So, fear not if you are a relational architect or DBA – your skills will still be required, despite what you might hear from the ‘big data’ and ‘NoSQL’ crowd.
Having said this, it’s going to be critical to get all of this stuff working together effectively as newer solutions start to enter the mainstream. It might therefore be worth all you RDBMS specialists out there extending your reach and apply your hard core data management skills elsewhere, especially as advocates of the new world order can sometimes be a bit naïve (warning: potentially offensive language behind this link).
CLICK HERE TO VIEW ORIGINAL PUBLISHED ON
![]()