
Readers have provided some great feedback during our latest workshop on a topic that has turned out to be close to many of your hearts – how best to manage an increasingly virtualised IT infrastructure. As part of the exercise, we ran one of our famous Freeform Dynamics polls so you could tell us how things currently stand in your organisation, and the results are in.
For many of you out there, the findings might make uncomfortable reading. But, as they say, you can’t tackle the problem until you know exactly what it is. With this in mind, you’ll hopefully get a heads up on a number of opportunities for driving improvement from reading on.
Before getting into the specifics, we have to issue the usual health warning about online surveys – respondents are self-selecting so the sample is going to be biased towards those with more of an interest in the topic. We can still learn a lot from the data, though; we just need to be careful not to take percentages relating to activity or intentions as a literal indication of what’s going on in the IT community as a whole.
So what did we find out?
Difficulties handling change
An obvious capability gap exists here. While frequent requests for new or enhanced services are part of the routine for most IT organisations, few of you are geared up to handle these optimally. Less than 1 in 20 strongly agreed in the poll that they were able to respond quickly to change requests, and less than a third thought they were good at it (Figure 1).
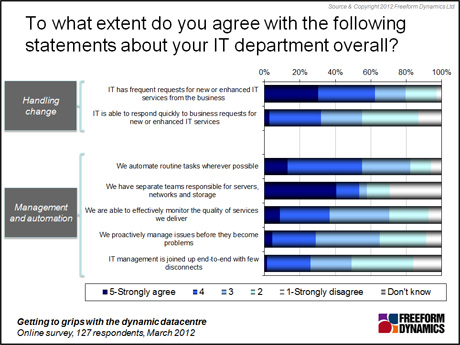
Figure 1
This is significant because previous research has demonstrated very clearly that being responsive to change requests from the business has a big bearing on both senior management and end user satisfaction with IT. This in turn affects how easy or hard life is for IT in terms of politics, funding and general support for IT-driven initiatives.
Meanwhile, other studies have highlighted that one of the biggest impediments to effective change management is fragmentation in various forms. Looking at the bottom part of the above chart, it is therefore telling that few IT organisations participating in our poll claim to have joined-up management, with operations teams often working separately too.
This is worth exploring further.
The connection between integration and more effective management
In order to investigate what’s going on here, we grouped poll respondents into two buckets. The first, which we have labelled “IT is responsive” are all those that agreed or strongly agreed that IT is able to quickly respond to requests for new or enhanced IT services from the business. In the “Others” group go all the rest who are ambivalent about this or who disagreed with the statement.
Comparing the groups, those with a responsive IT organisation are much more likely to have a single team that manages servers, storage and networks (Figure 2).
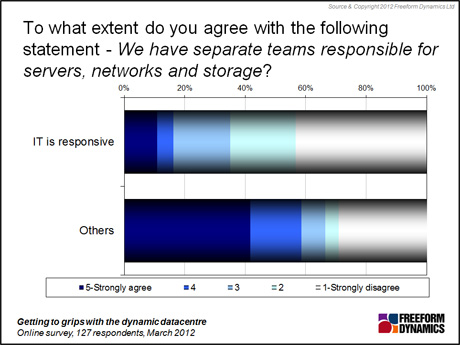
Figure 2
We need to be careful not to infer cause and effect from correlations such as this, but findings like these make sense when you think through the lifecycle of a change request. When separate teams are involved, particularly if there is a lot of demarcation between them, impact analysis and planning around dependencies can be harder.
Implementation is then often defined by the ‘do my bit and throw it over the wall’ principle, with a parochial attitude meaning teams may not consider the needs of their peers on the other side of that wall. Another symptom of disjointed teams is that often everything works serially rather than in parallel, sometimes with multiple iterations as one team rejects what another has just handed to them. All of this has a negative impact on time to respond as well as general efficiency.
We also saw a strong correlation in relation to management tools and processes. Responsive IT organisations are much more likely to have paid attention to integration of activity across various management areas such as servers, storage and networking (Figure 3).
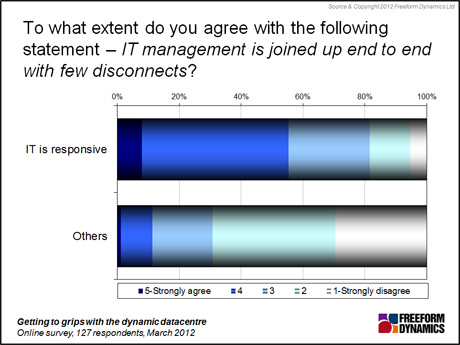
Figure 3
This is again understandable. Evaluating and implementing change requests is obviously going to be more of a challenge when configuration information relating to different types of infrastructure is stored and managed separately.
Effective monitoring and maintenance of service levels in an end-to-end manner can also be undermined when necessary data is coming from different tools and processes. It simply takes more time and effort to form a coherent view of what’s going on in any given scenario.
Symptom versus cause
The kind of research findings we have been discussing come up time and time again. When we look at them nicely laid out like this, we can intellectually see the link between fragmentation and poor performance. However, it’s the consequences of all this that are most front of mind when IT pros tell us what’s wrong in their world. Here, for example, is what came back from this latest poll in relation to virtual infrastructure management. Note the big emphasis on the symptoms with relatively little acknowledgement of the common underlying causes (Figure 4).
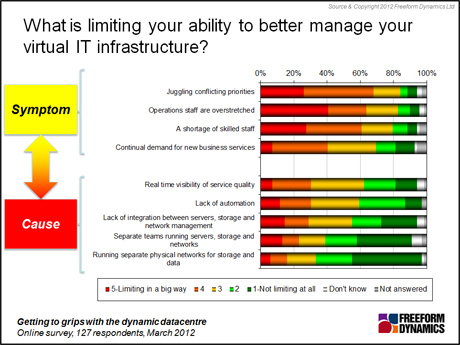
Figure 4
So what can you do about it?
Well the starting point is clearly to get a good handle on the question of symptom and cause in the way we have been discussing, then focus your efforts initially on tackling the underlying problems of team and tool fragmentation. Otherwise, you’ll just end up continually moving from one fire-fight to another, with little sustainable improvement from your attempts to make things better.
When it comes to disjointed teams, overnight reorganisation of the IT department to bring the various disciplines into the same working group is probably not going to be an option in most environments, especially larger ones. If nothing else, the political challenges are likely to be a big impediment.
Over time, however, this may be something to consider given the way in which virtualisation and dynamic architectures such as private cloud bring server, storage, networking and even application management dependencies to the fore. Indeed there are already examples of teams looking after virtual server estates becoming very storage and networking savvy out of necessity.
Meanwhile, making sure cross-discipline change and operational management processes are in place rather than each team doing their own thing in an uncoordinated manner is a useful initial step.
With regard to fragmented and disjointed toolsets, throwing everything out to implement a single suite or consolidated solution probably isn’t the answer. Apart from finding the money and time to do this, such a move can be very disruptive and risky. Instead, it’s usually better to invest in getting existing tools working better together.
The results from our poll, in fact, are consistent with this focus on tools integration rather than ‘rip and replace’. While there was a correlation between IT responsiveness and the use of a single toolset to cover servers, storage and networking (Figure 5), this was relatively weak compared to the previous one we saw (Figure 3) in relation to joining up what’s already in
place.

Figure 5
Making the case is critical
If integrating teams and tools was easy, we’d all have done it years ago. The reality is that investing in integrated management, while paying long term dividends, is not something that is as visible or exciting as the next new application project.
Making the case to stakeholders to spend time on driving improvements will therefore be vital to secure the funding and resources necessary to make a difference. With this in mind, we asked participants in our poll to tell us in their own words how they would describe the rationale for moving towards a more converged, dynamic IT infrastructure management approach.
Not surprisingly, we had a lot of feedback relating to cost savings come out of this, and some highlighted potential consequences that are often overlooked. This comment, for example, is very apt given a lot of the hype we hear about cloud computing being the magic bullet when it comes to IT efficiency:
“We can’t afford to keep wasting money like we have done otherwise the business will go elsewhere for IT services”
Also on the topic of cost, another respondent made a shrewd observation about hardware cost savings versus management overheads:
“Hardware is cheap so why virtualize? Configuration and management are the real issues.”
But some other strong themes also emerged, such as these focusing on rationale to do with improved service levels:
“Mainly for ease of management and maintenance; pooled storage and resources mean less down time which is critical for our business model”
“Consolidation & ability to respond to client requests”
“As the ’time to deploy’ continues to shrink, more converged and managed services are crucial to remain ahead of the game. The massive growth of virtualisation has changed the business expectation of IT timelines, and robust capacity management is now key to stable IT Operations.”
Coming back to the frequently highlighted ‘symptom’ of IT staff over-stretch, this reader’s motivation for exploring more joined up management is likely to strike a chord with many:
“A desperate hope that it will reduce the load on critical staff, who are impossible to recruit and hard to retain (thanks, HR!)”
Whichever way you look at it, getting things to work together better will start to pay dividends, whether it’s improved agility, lower costs, better staff satisfaction or keeping IT relevant to the business. So, can you really afford to keep putting it off any longer?
CLICK HERE TO VIEW ORIGINAL PUBLISHED ON
![]()
Content Contributors: Andrew Buss