
Many people tend to associate High Performance Computing (HPC) with exotic supercomputers with esoteric CPUs, high-end networking and storage fabrics, and custom applications simulating nuclear explosions, virtually crash-testing cars or designing the aerodynamics of the latest jetliner.
This vision is true for the high end of HPC, such as the computers that earn a position in the Top 500 list. But when we look at HPC in the enterprise, reality is more mundane. Commodity kit is favoured 3:1 over specialised equipment, and the performance and compatibility of x86 make it more desirable than Power, SPARC, Itanium and Cell for HPC.
At the same time, changes in the expectations of both the business and end users place more emphasis on performance from mainstream IT applications and systems that were nice-to-have only a few years ago. Certain workloads are industry specific. In financial services, for example, improvements in round-trip transaction times for trading applications are measured in nanoseconds. When looking at large-scale outsourced services such as payroll processing, reducing the time to complete a job can have a material impact on the risk associated with the service. Meanwhile, the faster business intelligence systems can analyse information and provide an answer, the broader their usefulness will be beyond traditional analytics.
Many systems have become embedded in the fabric of the company, and have assumed de-facto high-performance status even if nothing has been negotiated between the company and IT to formally support the systems. Microsoft Exchange is typical – when most PCs were desktops, few people complained if the system was down for half an hour, or if maintenance meant the server was not available at weekends or at night.
Now with mobile and web access, not only is the system expected to be up at all times, but it is also expected to perform snappily when users want to send or receive messages. The result is a by-product of the law of unintended consequences – if you give users more and more, even if little by little, they tend to complain louder when there is a problem.
Higher expectations have blurred of the line between traditional HPC and the high end of mainstream IT. To turn HPC experience into a fillip for demanding applications, what are the main areas to consider? First we have the question of relevance. Is HPC similar enough to mainstream IT to allow learnings to be ported across? In most cases the answer is a qualified yes – as we can see in the figure below.
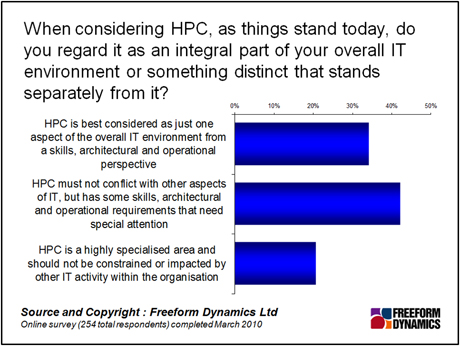
From our research, it is clear that the impact of HPC on mainstream IT is less to do with technology, and more to do with skills and operations management. Commodity hardware is widely regarded as suitable for HPC, with custom hardware reserved for the most demanding tasks. One of the reasons for this, apart from the direct cost advantage, is the pool of available skills. This has undoubtedly broadened the use of HPC, but the lack of high-end HPC skills has the potential to be a barrier to translating HPC experience into more general IT performance improvement.
HPC makes extensive use of UNIX and Linux, but Windows is less used – and often is ruled out. However, in the data centre, Windows tends to be the most used platform. This suggests an opportunity to translate success in HPC to boosting the performance of applications based on Microsoft platforms, but it will require investment in time and skills to achieve. Having said that, there is no reason to hold back from applying many of the general principles of HPC to Microsoft platforms and enhancing performance over time as the skills base builds.
What kinds of skills are we talking about? Looking beyond the specific configurations that can be made to the compute platform, HPC is often at the bleeding edge in terms of I/O and networking communications. It is no surprise to see that on the systems side, two of the most important investment areas in HPC implementations are networking fabrics and storage systems.
An often-overlooked aspect of HPC experience may be useful for more general performance IT, particularly with the advent of virtualisation. One of the fundamentals of HPC is getting the supply of electricity and the cooling right. These skills will be useful in virtualised environments, which are increasing the average utilisation of servers independently of demanding workloads, putting much of the same demands on facilities as an HPC installation. This is a complex area of systems implementation. Using skills and experience from HPC can help to take a virtualisation project forward more quickly and with less risk.
As more applications require high performance, HPC experience may be the key to unlocking bottlenecks that arise as more demands are placed on existing infrastructure. The challenge will be to ensure that the cost and scale of the solution is right for more general workloads and usage models. Given the costs involved are often high, and the lifetime long, this is an area that needs careful attention. A flexible approach to deployment and tiering, depending on application needs, will help to make best use of scarce and valuable resources – both for demanding applications and across the IT environment.
Content Contributors: Andrew Buss