
By Tony Lock
IT systems are subject to many of the same laws that govern the rest of the universe, however much IT vendors and end users might like to think otherwise. One of the most fundamental laws of physics, entropy, essentially states that unless energy from the outside is applied, the amount of disorder in an enclosed system will increase over time. Restated in IT terms, this means that the quality of data held in IT systems will deteriorate unless steps are taken to maintain its accuracy and consistency. Given that a majority of organisations rank the data they hold as a primary asset, what should you be doing to look after that data quality more effectively?
The value of data to organisations is clear, if often hard to quantify precisely. Few companies, however, have the processes and tools in place to ensure they maintain quality in their data, and certainly not as a matter of routine. Indeed, it is fair to say that most organisations tend to only act to ensure data quality when they implement new systems, undergo a major update, when they need to integrate with another platform, or when something goes disastrously wrong. As a consequence, the accuracy of the information held in IT systems, even that in business critical databases, will ‘drift’ over time.
Recently, Freeform Dynamics looked at data quality from the perspective of IT professionals and of line of business managers.
Reasons for why data quality degrades over time include typing mistakes when editing records, software bugs or communications glitches introducing errors, unverified external data sources being used to update or supplement information, as well as data records not being updated at all, due to pressure of work or simple oversight. Given that many of these factors are down to human error, there is an opportunity for automated IT solutions to mitigate / remediate or remove such errors and data degradation.
The consequences of poor data quality are not hard to find and nearly all end users, across all lines of business, recognise them. Depending on your business examples could include products being shipped to the wrong address, as the address updated in the sales system had not been synchronised with the Logistics database, or the customer service desk being unable to respond quickly when a client calls due to information inaccuracies etc.
Another instance could be different internal systems providing a senior manager with different results, meaning that they must then spend additional time working out which one is correct. Such problems inevitably result in users spending more time on routine activities than would be needed if organisations had addressed their data quality issues. Perhaps more importantly, poor data quality can lead to organisations taking decisions based on inaccurate or out of date information, potentially with expensive consequences (Figure 1).
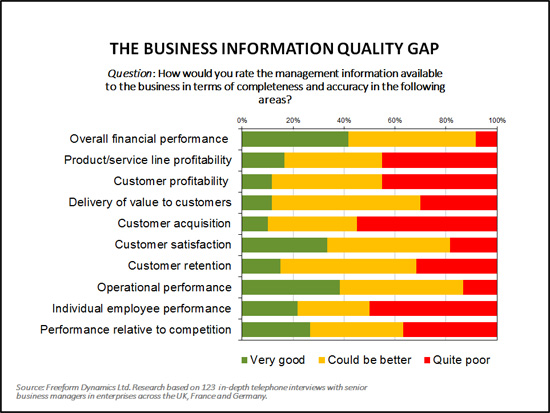
Figure 1
This makes it hard to understand why so few organisations implement formal processes to preserve data quality over time.
There is no ’silver bullet’ IT solution, which delivers data quality without effort. Nevertheless, there are many steps which IT and business managers are able to take to improve matters.
The starting off point for improving data quality and integrity is deciding just what data source, or sources, should be regarded as holding the ‘truth’ when considering any data record. This sounds simple. Alas, it is rarely straightforward, not least because so few organisations maintain all essential information in a single data store or database. Organisations also need to recognise that elements of internal politics may come into play. Thus, it is essential that IT consults with line of business managers in order to avoid the ‘My data is more important / complete / ‘rich’ / valid / up to date than yours’ discussion.
Once decisions have been made as to which sources are reliable, the next step is to create a high level architecture that describes the mechanisms by which IT will maintain data quality as part of routine IT and business operations. This is quite different to occasional attempts to ‘cleanse’ data sets.
At heart, the objective is to build an IT environment which is supported by operational processes, where important data is verified and, where suitable, enriched at the time it is created, captured or updated. Most data repositories will probably still benefit from periodic auditing, cross referencing and validating to ensure that quality is maintained. The challenge is to make such processes both simple to undertake and cost effective. Fortunately, tools to improve data cleansing have advanced dramatically in recent years. In addition, there are service providers, including cloud vendors, which specialise in this area. Equally important, best practice guidance is emerging.
In this context, remember that it is essential that each organisation considers whether all data requires the same level of cleansing and integrity maintenance. Given the fact that data cleansing and integrity checking involves effort and, therefore, costs, managers should bear in mind that not all data is of equal business value. But which data belongs in which category (and why) should be a business decision, not an IT one.
Data is the lifeblood of many organisations. Impure data is like impure blood—not good for the system. If your organisation is one which does not recognise the effects of entropy on data it is time to step back and consider the possible consequences and costs. Your objective is to deliver appropriately accurate data quality on a continuous basis, rather via periodic data cleaning projects, which may leave you vulnerable between times.
CLICK HERE TO VIEW ORIGINAL PUBLISHED ON
![]()