
The DevOps movement is supported by a whole range of tools, and is particularly well served by the Open Source community. Whether it’s Jenkins, Nexus, Maven or the many other OSS projects that enable the development process, or Chef, Puppet, Ansible, SaltStack, etc. used to automate operations, those working in a DevOps environment are spoiled for choice.
As I discussed in a previous post, however, as you look to scale up your DevOps initiative to handle more applications, higher throughput and greater overall complexity, it’s sometimes necessary to introduce tooling that works at a higher level. Project and portfolio management to enable a more structured approach to dealing with the business dimension, and release automation solutions to provide over-arching orchestration capabilities, are both examples.
But as you become more adventurous with DevOps, gaps can also become evident in the core tooling layer. One of these came into sharp focus for me during a recent conversation I had with Jes Breslaw Director of Marketing and Strategy for Delphix in EMEA.
According to the company website, “Delphix software enables Data as a Service, within a firm’s on-premise, private, or public cloud infrastructure”. It’s a very impressive sounding claim, but if you have no idea what it means, don’t worry – I didn’t either until I had the briefing. As it turns out, the concept behind the solution is actually pretty straightforward.
In order to appreciate what Delphix does and how it does it, consider the number of times data is replicated within your organisation to meet various application lifecycle needs. Copies of live data from an ERP system, for example, may be used to populate databases underpinning development, test and staging landscapes as part of the periodic upgrade or migration process. And in a fast-moving software development or DevOps environment, even more clones and subsets of the same data set are required to support teams of developers, testers and operations staff working on parallel continuous delivery streams.
Managing all of this through export, import or even bulk copy operations is both time consuming and error prone. It’s also very costly from a raw storage perspective, particularly when dealing with large datasets. And, of course, along the way you need to worry about security and privacy if data originates from live systems.
Delphix allows you to cut through most of these challenges with an elegant solution based on a form of data virtualisation. This typically starts by connecting to your production sources using standard APIs and creating a one-time compressed copy of your production data. Using the same APIs, and without disruption to the live environment, changes in production data are then continually recorded from that point onwards to keep the second copy up to date.
From here, Delphix uses block sharing to enable the creation of multiple virtual copies where you would otherwise have made physical copies. You can stand up these virtual instances as of any point in time, in minutes, and can refresh or rewind them at will – ‘time machine’ style. This brings similar agility and cost benefits to data as hypervisors brought to your server estate.
The following diagram (reproduced courtesy of Delphix) summarises how things work in visual form (click to enlarge):
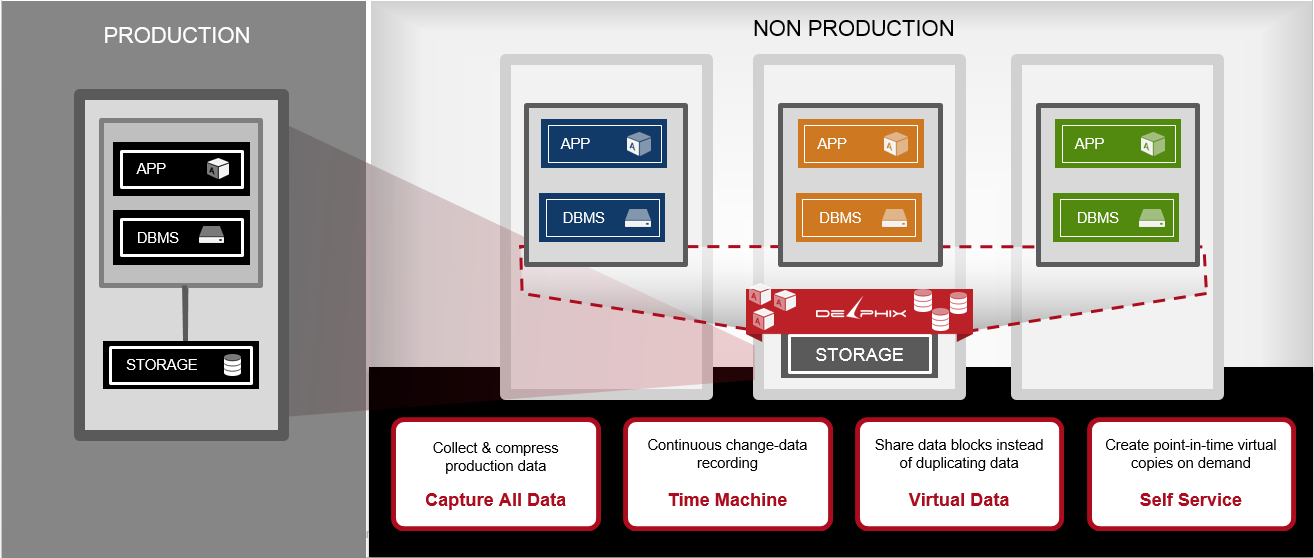
The advantages of this approach are pretty easy to understand. Firstly, being able stand up, tear down or reset a virtual environment quickly and with the minimum of effort makes a huge difference in a DevOps environment, where you want to be able to iterate through build, test, release and promote cycles rapidly and freely. Secondly, because it’s now so easy and cost-efficient to create and maintain many more environments, wait times on key resources are largely eliminated, allowing projects to be parallelised much more effectively. Thirdly you need a fraction of the raw storage capacity as each virtual dataset only takes up the space required to hold delta and log information, which can free up significant budget.
Now you may be thinking that the idea of streamlining data provisioning through a thin virtualisation layer is not new – indeed most mainstream storage vendors provide solutions or features within broader solutions to do something of this kind. What’s different here is that Delphix is coming at the problem from the top down, i.e. its focus is on addressing the needs of application teams as well as storage professionals. This leads to some additional benefits over and above the ones already mentioned that are worth calling out.
Delphix, for example, allows data masking to be implemented as an integral part of its data virtualisation approach, essentially obfuscating information to assure security and privacy without the need for separate tools and processes. Once the masking policy is created it is applied continuously as further data is pulled across from production databases. This minimises potential legal and reputational risks arising from the use of live data in non-production systems, and removes a tedious problem that often distracts development teams from their core activities.
The abovementioned rapid provisioning and ‘time machine’ functionality is then implemented through a self-service interface, which is great for developers and testers who want to go back to a recent point in time to re-run an operation without having to reset the entire virtual dataset or rely on the data back-up and archive teams. Beyond this, there’s packaged application awareness (e.g. SAP, Oracle, etc) and ‘good citizen’ style integration with service virtualisation tools, release management software and other solutions frequently found in the DevOps tool-chain.
Pulling it all together what I liked about the Delphix story was not so much the functionality – pretty much every element of it is available in one form or another elsewhere – but the way the whole thing has been designed to fit into the modern collaborative IT environment. The needs of traditional roles are respected, from storage management through DBA to application specialist, with self-service facilities allowing everyone to get out of each other’s way. From the research I have been doing into DevOps practicalities lately, this is pretty much the definition of what’s required to support the kind of effective continuous delivery aspired to by so many.
Dale is a co-founder of Freeform Dynamics, and today runs the company. As part of this, he oversees the organisation’s industry coverage and research agenda, which tracks technology trends and developments, along with IT-related buying behaviour among mainstream enterprises, SMBs and public sector organisations.




Have You Read This?
From Barcode Scanning to Smart Data Capture
Beyond the Barcode: Smart Data Capture
The Evolving Role of Converged Infrastructure in Modern IT
Evaluating the Potential of Hyper-Converged Storage
Kubernetes as an enterprise multi-cloud enabler
A CX perspective on the Contact Centre
Automation of SAP Master Data Management
Tackling the software skills crunch