
All too frequently the IT industry gets caught up in a whirlwind of marketing stories indicating that the next revolution bringing answers to peace, happiness and world hunger has begun. Freeform Dynamics recently published a report looking at this year’s ‘must have’, namely big data and how this will influence various storage technologies as things move forwards.
One of the biggest challenges with big data hype is actually defining just what the expression means. Indeed after ‘cloud’, big data has become one of the most hyped terms in use in the IT world, but the reality is that it applies to a two quite different things: dealing with the sheer weight of data growth; and being able to understand the information hidden within different data sources to guide business decision.
When we look at managing the data explosion, we can boil it down to three core elements that are commonly referred to as the ‘Three Vs’ – namely Volume, Velocity and Variety. The ‘3Vs’ makes for a nice marketing phrase, but it needs some explanation. More importantly it doesn’t take account of the fact that much of the value in the data being generated by IT systems today has a low ‘signal to noise’ ratio, making it difficult to locate the nuggets of valuable information amongst the huge amount of data. A more complete discussion can be found here.
The real value of big data comes from the rapid analysis of data sources to provide information the organisation can exploit to generate new value or make better operational choices. This value is enhanced when this can be achieved in close to real time. Whilst our survey results highlight that the crown jewels of organisational data are still held in structured sources, many organisations recognise that they are holding rapidly growing volumes of data in other forms, much of which is not exploited to anything like its fullest extent. This is the challenge that big data is attempting to address.
In essence big data seeks to dig valuable information from the large amounts of data organisations are now generating every day. The data to be analysed may utilise feeds from both structured and unstructured sources, but the key point is that the value of information to be mined may not be found in rich seams, but rather needs to be sifted from very large volumes of data.
To analyse these large volumes of data, possibly taken from multiple sources, a number of information management technologies may be employed. It is worthwhile noting that very few, if any of the new data management technologies coming to market today and that have surfaced over the past few years are targeted solely at the big data space. Indeed, almost all data and information management solutions are likely to be utilised in big data projects as well as other, more ‘mainstream’ business uses.
In this context, the figure below is interesting, revealing as it does both current usage levels of a variety of such tools and platforms along with expectations for changes in usage levels expected to occur in the next three years. It should be noted that the self-selecting nature of web surveys makes it likely that both the usage levels of ‘new solutions’ as well as projections for their future usage are likely to be over-represented as people interested in the area being surveyed are more likely to take part.
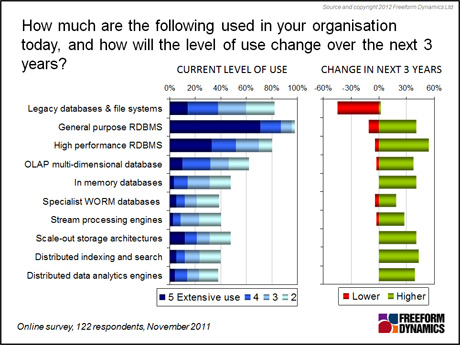
As can be seen, apart from legacy databases and file systems there is an expectation that already well-established information management technologies such as relational database management systems will continue to enjoy growth in usage in the coming years. These will increasingly be complemented by less well-established, but long available solutions such as in memory database systems, WORM databases and OLAP multi-dimensional databases, which are expected to expand considerably from their smaller foundations.
The more specialist platforms that are now frequently associated with ‘big data’, but which are by no means exclusively utilised in this context, are starting from much lower installed bases. Of these,
a range of scale-out storage solutions enjoys the strongest adoption so far, but these are still clearly in their infancy in enterprise use, never mind in big data solutions. Stream processing, distributed indexing and distributed analytics engines are only just starting to be rolled out.
But like their well-established information management solutions, the expectation is that all such systems will enjoy wider usage in the coming years. It can also be argued that should the business value of ‘big data’ solutions garner wider recognition, that that take up of the various information management systems could expand even more rapidly, especially as the generation of data as a whole shows no signs of abating.
What is clear is that neither ‘big data’ itself nor the use of any new information management or storage technologies are likely to mean an end to the use of established data management solutions. If anything, the reality is just the opposite. The study also shows that the knowledge levels amongst IT professionals as a whole of many new storage and information management systems today is still very low, especially of the newer technologies. This lack of knowledge is acting as a brake on take up of many new data management solution offerings. But the adoption of new solutions, whether related to big data projects or to meet other business needs does not mean the end of most established storage platforms nor the end of tried and trusted database management solutions.
CLICK HERE TO VIEW ORIGINAL PUBLISHED IN
![]()
Through our research and insights, we help bridge the gap between technology buyers and sellers.




Have You Read This?
From Barcode Scanning to Smart Data Capture
Beyond the Barcode: Smart Data Capture
The Evolving Role of Converged Infrastructure in Modern IT
Evaluating the Potential of Hyper-Converged Storage
Kubernetes as an enterprise multi-cloud enabler
A CX perspective on the Contact Centre
Automation of SAP Master Data Management
Tackling the software skills crunch